Tracing and profiling machine learning dataflow applications on GPU
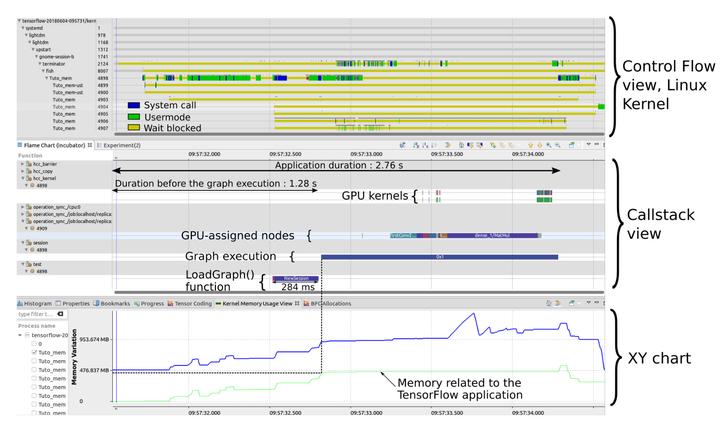 Image credit: Unsplash
Image credit: Unsplash
Abstract
Recently, increasing computing capabilities have been required in various areas like scientific computing, video games and graphical rendering or artificial intelligence. These domains usually involve the processing of a large amount of data, intended to be performed as fast as possible. Unfortunately, hardware improvements have recently slowed down. The CPU clock speed, for example, is not increasing much any more, possibly nearing technological limits. Physical constraints like the heat dissipation or fine etching are the main reasons for that. Consequently, new opportunities like parallel processing using heterogeneous architectures became popular. In this context, the traditional processors get support from other computing units like graphical processors. In order to program these, the dataflow model offers several advantages. It is inherently parallel and thus well adapted. In this context, guaranteeing optimal performances is another main concern. For that, tracing and profiling central processing and graphical processing units are two useful techniques that can be considered. Several tools exist, like LTTng and FTrace that can trace the operating system and focus on the central processor. In addition, proprietary tools offered by hardware vendors can help to analyze and monitor the graphical processor. However, these tools are specific to one type of hardware and lack flexibility. Moreover, none of them target in particular dataflow applications executed on a heterogeneous platform.